



 Intro
Intro
서버 응답시간에 큰 영향을 미치는 부분은 주로 네트워크 통신과 데이터베이스 I/O입니다.
이번 글에서는 캐싱을 통해 데이터베이스 I/O로 인해 발생하는 오버헤드를 줄이는 방법에 대해 얘기해보겠습니다.
Why Caching?
In computing, a cache is a hardware or software component that stores data so that future requests for that data can be served faster. — Wikipedia
캐시는 빠른 응답과 비용 절약을 위해 사용하는 임시 데이터입니다.
서버에서 캐시를 사용하는 상황에 대해 먼저 알아봅시다.
클라이언트-서버 모델은 다음과 같이 구성되어 있습니다:
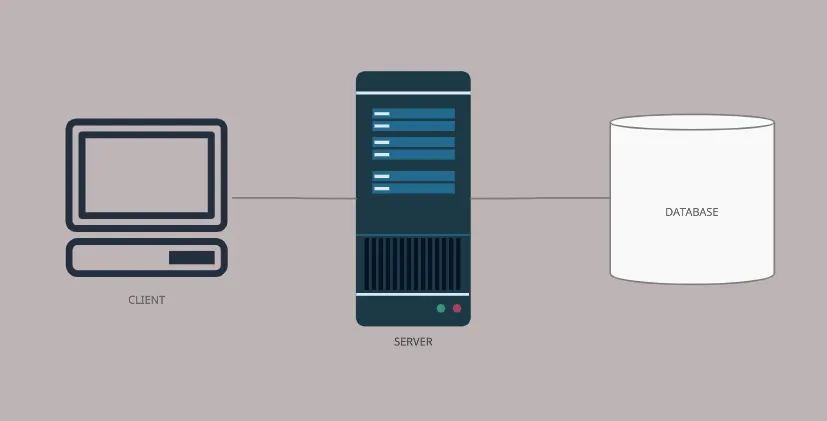
클라이언트의 요청으로 특정 데이터가 필요한 경우 서버는 데이터베이스에 쿼리한 뒤 결과를 반환합니다.
만약 요청하는 데이터의 캐시가 존재한다면 데이터베이스에 쿼리하지 않고 캐시로부터 데이터가 반환됩니다.
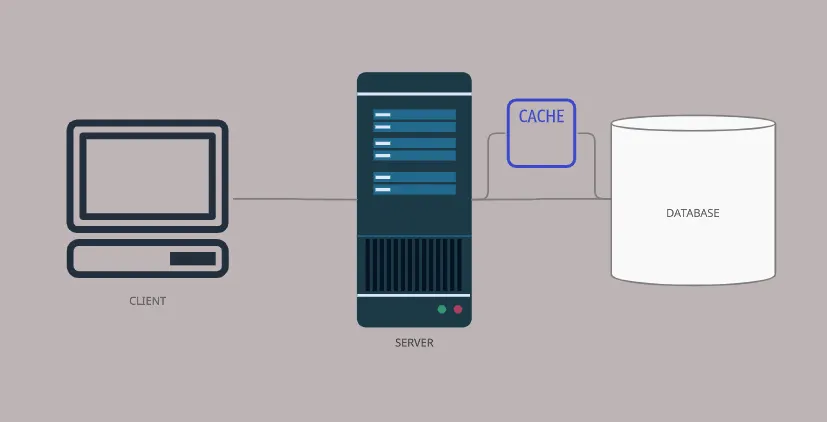
캐싱(Caching)은 하드웨어나 소프트웨어 전반에 사용되는 기술입니다.
서버-데이터베이스 뿐만 아니라 클라이언트나 CDN에서도 캐싱을 사용합니다.
이번 글에서는 서버-데이터베이스 캐싱만 다룹니다.
요청한 데이터의 캐시가 없다면 어떻게 될까요?
이런 경우 데이터베이스에 쿼리가 수행되어 반환되고 결과는 캐싱됩니다.
캐시는 다음 요청에 이용됩니다.
요청한 데이터의 캐시가 있는 경우 Cache Hit로 표현하고, 없는 경우 Cache Miss로 표현합니다.
캐시는 어떻게 관리될까요?
캐시는 임시 데이터입니다. 따라서 캐시를 저장할 때 캐시가 만료되는 시간(expire time; TTL)을 명시합니다.
캐시는 해당 시간 내에서만 유효하고 만료 시간이 경과하면 사용할 수 없습니다.
캐시에 만료되는 시간을 두는 이유는 캐시가 source of truth가 아니기 때문입니다.
만약 데이터베이스의 내용이 바뀐다면 캐시도 바뀌어야 합니다.
Cache Invalidation 부분에서 더 자세하게 얘기하겠습니다.
지금은 원본 데이터가 바뀌면 캐시도 바뀌어야 한다는 사실만 기억합시다.
왜 캐시를 사용하는 것일까요?
캐시를 사용하면 데이터베이스를 읽을 때 발생하는 I/O 오버헤드를 줄일 수 있습니다.
캐시는 보통 Redis와 같은 In-Memory 데이터베이스를 사용합니다.
In-Memory 데이터베이스는 메모리를 사용하기 때문에 일반적인 데이터베이스 보다 데이터를 읽는 속도가 빠릅니다.
따라서 캐시는 데이터베이스에서 데이터를 읽는 것보다 훨씬 빠르게 결과를 반환합니다.
그럼 모든 데이터를 캐싱하는 건 어떨까요?
In-Memory DB를 쓰면 요청을 빠르게 처리할 수 있지만 메모리 특성상 데이터가 소실될 위험이 있습니다.
또 메모리 사용은 비싼 작업이기 때문에 방대한 양의 데이터를 모두 메모리에 적재하는 것은 비용이 많이 듭니다.
Redis의 경우 persistence를 보장하기 때문에 메인 데이터베이스로 사용할 수도 있습니다. →링크
그렇기 때문에 데이터의 특성에 따라 데이터베이스와 캐시를 적절히 사용하는 것이 매우 중요합니다.
캐싱 전략을 올바르게 수립하면 적은 비용으로 큰 퍼포먼스를 향상을 기대할 수 있습니다.
What to Cache
어떤 데이터를 캐싱하는 것이 좋은지 알아봅시다.
Charateristic
캐싱하기 좋은 데이터의 특성은 다음과 같습니다:
1.
자주 바뀌지 않는 데이터
2.
자주 사용되는 데이터
3.
자주 같은 결과를 반환하는 데이터
4.
오래 걸리는 연산의 결과
1
자주 바뀌지 않는 데이터의 경우, 한 번 캐시로 저장하면 메모리에서 읽어서 빠르게 사용할 수 있습니다.
앞서 얘기했듯 원본 데이터가 바뀌면 캐시도 바꿔야 합니다.
자주 바뀌지 않는 데이터의 캐시는 오래동안 사용이 가능하기 때문에 캐싱하는 것이 효율적입니다.
2
자주 사용되는 데이터도 캐싱하기 좋습니다.
한 번 캐싱을 해놓으면 캐시를 사용하여 다수의 응답을 효율적으로 처리할 수 있을 것입니다.
다만 자주 사용될 지라도 매번 결과 값이 다르다면 오히려 캐싱하지 않는 것이 낫습니다.
만약 일정시간 동안 데이터가 변하지 않는 것이 보장되면 해당시간 만큼의 TTL로 짧은 캐시를 생성하면 됩니다.
예를 들어 검색처럼 새로 요청 하더라도 일정시간동안 같은 결과가 반환되는 경우에 해당합니다.
3
자주 같은 결과를 반환하는 데이터의 경우도 캐싱을 적용하기 좋습니다.
예를 들어 특정 argument의 조합에 따라 결과가 일정한 경우에 해당합니다.
이럴 때는 각 argument의 조합을 key로 연산 결과를 캐싱하면 됩니다.
캐시는 Key-Value 형태로 저장합니다.
4
오래 걸리는 연산의 경우 결과도 캐싱하는 것이 효율적입니다.
무거운 연산이 반복적으로 계산되어야 한다면 연산의 특성에 맞게 결과를 캐시하는 것이 효율적입니다.
또는 사전에 별도의 프로세스에서 배치 작업을 수행하여 결과를 미리 캐싱 해놓을 수도 있습니다.
이 밖에도 일반적인 쿼리나 연산보다 캐싱할 때의 비용이 더 적다면 캐싱을 사용하면 됩니다.
위의 예시들에서 알 수 있듯이 어떤 데이터를 캐싱할 지 결정할 때, 규격화 된 규칙이 있는 것이 아닙니다.
로그 분석이나 프로파일링을 통해 캐시를 적용할 함수나 API를 찾아낼 수도 있습니다.
그러나 모든 사항을 고려하여 캐싱을 적용할지, TTL을 얼마나 정할지 등의 결정은 개발자의 선택이 중요합니다.
Schema
캐싱하는 데이터의 형태는 크게 두 종류로 나눌 수 있습니다:
1.
원본 데이터
2.
연산 결과 또는 응답 데이터
1
첫 번째는 원본 데이터를 그대로 캐싱하는 것입니다.
user1이라는 하나의 객체에 대한 정보를 캐싱했다가 user1이 필요한 상황에 호출하여 사용합니다.
user1 데이터가 사용되는 다양한 경우에 캐시를 사용할 수 있기 때문에 범용적인 방법입니다.
2
두 번째는 연산 결과 또는 응답 데이터를 캐싱하는 것입니다.
user1 데이터와 다른 여러가지 데이터를 혼합하여 생성된 데이터를 캐싱하는 방법입니다.
예를 들어 serialized 된 JSON 응답을 캐시로 생성하는 것입니다.
이런 캐시는 특정 함수나 API에 종속되기 때문에 재사용성이 낮습니다.
또 다른 단점은 중복되는 값이 여러 개의 캐시 안에 존재할 수 있습니다.
예를 들어 유저의 프로필이 본인이 볼 때와 다른 사람이 볼 때 다른 format으로 serialize 된다고 합시다.
위의 상황에서 각각의 데이터를 캐싱했을 때 username과 같은 값이 중복될 수 있습니다.
이런 중복된 값이 변경된 경우 두 개의 캐시 모두 지워주어야 합니다.
대신 결과를 캐싱하면 원본 데이터를 캐싱하는 것보다 단일 함수 또는 API의 퍼포먼스 향상 효과가 큽니다.
다만 앞서 설명했듯이 invalidation 처리가 번거로워질 수 있기 때문에 이를 유의하여 사용해야합니다.
Stale Cache Handling
There are only two hard things in Computer Science: cache invalidation and naming things. — Phil Karlton
다시 말하지만 캐시는 빠른 응답을 위한 임시 데이터기 때문에 원본 데이터에 종속적입니다.
원본 데이터가 바뀌면 이전에 생성된 캐시는 더 이상 쓸모가 없어집니다.
오히려 오래된 캐시가 남아있으면 잘못된 데이터를 제공하게 됩니다.
따라서 데이터를 캐싱하는 것만큼 유효하지 않은 캐시를 지우는 것이 중요합니다.
Cach Invalidation
캐시 무효화(Invalidation)는 요청에 대해 캐시 데이터가 사용되어야 할지 아닐지를 결정하고 항상 최신의 데이터를 반환하도록 하는 일련의 과정입니다.
일반적인 캐시 무효화 방법은 다음과 같습니다:
1.
Expiration Time
캐시가 생성될 때 지정한 TTL에 의해 캐시의 수명이 결정되고 수명이 다한 캐시는 사용되지 않습니다.
가장 일반적인 캐시 무효화 전략입니다.
TTL을 보수적으로 정했을 때, 해당 시간이 지나면 최신의 데이터가 반환되기 때문에 안전한 방법입니다.
캐시를 잘 관리할 자신이 없다면 TTL을 짧게 정하는 것이 좋습니다.
2.
Freshness Caching Verification
별도의 검증 절차를 통해 캐시가 유효한지 확인하는 방법입니다.
예를 들어 원본 데이터가 업데이트 된 시간과 캐시가 생성된 시간을 비교하여 캐시의 유효성을 판별합니다.
단점은 캐시가 사용될 때마다 추가적인 확인 절차를 수행하기 때문에 이에 따른 오버헤드가 발생합니다.
3.
Active Application Invalidation
데이터가 수정되는 코드가 수행될 때마다 백엔드에서 연관된 캐시를 무력화하는 방법입니다.
캐시를 세밀하게 관리할 수 있기 때문에 이상적으로 설계되었을 때 가장 좋은 효율을 발휘합니다.
1번 방식이 수동적인 방법인데 비해 아주 능동적인 방법입니다.
별도의 코드를 통해 캐시를 컨트롤 하기 때문에 가장 에러가 발생하기 쉽고 관리가 까다롭습니다.
캐시를 능동적으로 관리할 때 다음의 두 가지 방식으로 오래된 캐시를 처리할 수 있습니다:
1.
새로운 데이터 업데이트 하기
2.
오래된 캐시 지우기
1
첫 번째 방법은 원본 데이터의 변화에 따라 캐시를 수정하는 방법입니다.
캐시 중 일부가 변경 되었을 때 캐시의 전체를 다시 생성하는 것보다 일부만 수정하는게 효율적인 경우입니다.
참조되고 있는 데이터가 많은 경우에는 일일이 캐시를 수정하는 것이 비효율적일 수도 있습니다.
2
이보다 일반적인 방법은 캐시를 지우는 것입니다.
원본 데이터가 변경되었을 때 업데이트 할 캐시가 많으면 일일이 캐시를 수정하기보다 지우는 것이 효율적입니다.
단점은 데이터 중 일부만 변경된 경우에도 전체를 지우고 다시 생성하기 때문에 약간의 비효율성이 발생합니다.
캐시가 생성되는 과정이 비싼 연산이 아니라면 수정하기 보다 지우는 것이 관리 측면에서 용이합니다.

