



Intro
데이터 기반 의사결정(DDDM)을 위해 점차 비지니스 인텔리전스(BI)가 강조됩니다.
많은 회사에서 구성원에게 직접 데이터를 추출하고 분석하는 능력을 요구하기도 합니다.
SQL은 더 이상 데이터 분석가의 전유물이 아닙니다.
개발자, 퍼포먼스 마케터, UI/UX 디자이너 그리고 SQL을 배우고 싶은 모든 사람들을 위한 글입니다.
많은 분들이 처음 SQL을 배울 때 이해하기 힘들어하는 부분에 대해서 설명합니다.
또 intermediate 수준의 SQL을 구사하기 위해 반드시 알아야하는 SQL의 특성에 대해 다룹니다.
본격적으로 시작하기 전 다음 네 가지 체크리스트에 답해보세요:
SELECT, FROM, WHERE, ORDER BY를 이용한 단순한 형태의 쿼리가 가능하다.
SQL에서 스칼라(scalar)라는 개념을 알고 있다.
GROUP BY, JOIN과 같은 구문을 능숙하게 사용할 수 있다.
CASE 구문이나 WINDOW 함수를 능숙하게 사용할 수 있다.
이 글을 읽기 위해서는 적어도 위의 네 가지 중 첫 번째 항목에 해당하는 기본 쿼리를 할 줄 알아야합니다.
나머지 세 가지 항목에 대해서도 이미 알고 있다면 이 글이 너무 쉬울 수 있습니다.
만약 아무것도 해당하지 않는 독자라면 먼저 SQL 기본 문법부터 학습할 것을 권장합니다.
이 글에서는 기초 SQL 구문(SELECT, FROM, WHERE, ORDER BY 등)에 대한 설명은 생략되어 있습니다.

그럼 본격적으로 시작해봅시다.
SQL의 두 가지 특징
SQL이 일반적인 프로그래밍 언어와 다른 중요한 두 가지의 특성이 있습니다.
반드시 다음 두 가지 특성을 이해해야 SQL을 올바르게 사용할 수 있습니다:
•
SQL은 선언형(declarative) 언어다.
•
SQL은 집합 지향형(set-oriented) 언어다.
1. 선언형(declarative) 언어
프로그래밍 언어 패러다임
어떤 프로그램(우리의 경우, 관계형 데이터베이스)을 동작시키는 언어에는 두 가지 패러다임이 있습니다:
•
명령형(Imperative) 패러다임
•
선언형(Declarative) 패러다임

갑자기 프로그래밍 이야기가 나왔다고 전혀 겁 먹을 필요가 없습니다.
예시를 통해 이해하면 충분합니다.
일반적인 프로그래밍 언어(C계열 언어, Java, Python 등)는 명령형 언어에 해당하고,
이와 반대로 SQL은 가장 대표적인 선언형 언어입니다.
명령형 언어는 명령어를 통해 프로그램의 상태를 제어해 원하는 결과를 얻어내는 반면
선언형 언어는 프로그램의 제어에는 신경쓰지 않고 원하는 결과에 대해서만 묘사합니다.
예시를 통해 알아봅시다.
만약 차를 한 잔 준비한다고 할 때 두 가지 패러다임은 다음과 같이 서로 다른 방식으로 사용해야 합니다:
쉬운 비교를 위해 명령형 언어 중 하나인 절차형 언어로 예시를 들겠습니다.
절차형 언어(⊂명령형 언어)
1.
주방에 간다.
2.
잔을 하나 준비한다.
3.
물을 끓인다.
4.
잔에 끊인 물과 티백을 넣는다.
선언형 언어
1.
차를 한 잔 준비한다.
절차형 언어는 각 단계 별로 어떻게 동작할 지를 명령한다면
선언형 언어는 어떻게 동작하는지는 시스템에게 맡기고 무엇을 원하는 지만 전달합니다.
SQL을 예시로 다시 설명해보겠습니다:
SELECT *
FROM JOBS
SQL
복사
위의 SQL을 보면 JOBS 테이블에서 전체 데이터를 조회해달라고 요청하고 있습니다.
조회할 열을 *로 선언하면 데이터베이스는 JOBS 테이블을 찾아서 어떤 열들이 있는 지 확인합니다.
그리고 모든 열에 대한 전체 행의 값을 알아서 출력해줍니다.
따라서 원하는 결과를 얻기 위해서는 데이터베이스에 요구할 내용을 잘 묘사하는 것이 중요합니다.
초보자들이 SQL을 어려워하는 이유는 복잡한 요구사항을 잘 묘사하는 방법을 모르기 때문입니다.
차를 준비하는 예시에 몇 가지 조건을 추가하겠습니다:
절차형 언어(⊂명령형 언어)
1.
2층에 있는 주방에 간다.
2.
빨간 잔을 세 개 준비한다.
3.
물을 끓인다.
4.
끊인 물을 세 개의 잔에 나누어 담는다.
5.
두 개의 잔에 홍차, 한 개의 잔에 녹차를 넣는다.
선언형 언어
1.
2층 주방에서 빨간 잔 세 개에 두 잔의 홍차와 한 잔의 녹차를 준비한다.
요구조건이 복잡해질 때 절차형 언어에서는 절차가 늘어나지만 개별 명령의 난이도가 크게 어려워지지 않습니다.
그런데 선언현 언어에서는 하나의 구문 안에 요구조건을 모두 표현해야 하기 때문에 요구조건이 복잡해질수록 명령의 난이도가 어려워집니다.
위의 예시보다 복잡한 수십 가지의 절차를 하나의 문장으로 줄인다고 상상해보세요.
SQL로 복잡한 요구 사항을 표현하기 어려운 이유 중 하나입니다.
그렇다면 SQL을 통해 복잡한 요구조건을 잘 묘사하려면 어떻게 해야할까요?
SQL의 특징을 이해하고 SQL에 맞는 사고방식을 가져야합니다.
식(expression) vs. 구문(statement)
SQL에 익숙하지 않은 사람들은 어떤 문제를 풀 때 구문의 조합으로 해결하려고 합니다.
이러한 경향은 프로그래밍을 할 줄 아는 사람일수록 강하게 나타납니다.
보통의 프로그래밍 언어는 여러가지 구문의 조합으로 명령을 전달하기 때문입니다.
하지만 SQL을 잘 쓰기 위해서는 구문보다 식을 잘 다루어야 합니다.
식과 구문의 차이
식은 2 + 2, 'abc', TRUE 등과 같이 값으로 평가됩니다.
반면 구문은 무언가를 동작시킵니다. SQL에서는 SELECT 구문이 대표적입니다.
구체적인 예시를 들어보겠습니다.
SQL을 통해 유저가 대학생인 경우 학교 이름을 출력하고, 직장인인 경우 직장명을 출력한다고 해보겠습니다.
대학생인지 직장인인지 여부는 occupation 값으로 구분하겠습니다
SQL의 초보자인 경우 다음과 같은 SQL을 작성할 가능성이 높습니다:
SELECT
university
FROM
users
WHERE
occupation = 'student'
UNION
SELECT
company
FROM
users
WHERE
occupation = 'employee'
SQL
복사
구문으로 문제를 해결한 경우입니다.
대학생과 직장인을 WHERE 절의 조건으로 지정하여 각각의 집합을 구한 뒤 UNION으로 결과를 합칩니다.
이런 쿼리는 전체 테이블의 탐색을 두 번하기 때문에 효율적이지 않고 조건이 많아질수록 가독성이 떨어집니다.
index를 활용하면 WHERE와 UNION을 이용하는 방식이 효율적인 경우도 있습니다
위의 문제를 해결하는 최적의 방법은 CASE 구문을 이용하는 것입니다.
CASE 구문을 활용하여 만든 동일한 쿼리는 다음과 같습니다:
SQL에서 동일하다는 의미는 동일한 결과를 출력한다는 뜻입니다.
SELECT
CASE WHEN occupation = 'student' THEN university
WHEN occupation = 'employee' THEN company
END
FROM
users
SQL
복사
구문 보다 표현식을 이용하여 해결한 경우입니다.
WHEN 이후에는 조건을, THEN 이후에는 조건을 만족했을 때 표현될 결과(열)를 지정해줍니다.
주의 할 부분은 조건인 occupation = 'student'와 결과인 university가 모두 식이라는 점입니다.
occupation = 'student' 식은 참 또는 거짓으로 평가됩니다.
university 역시 문자열로 평가되는 식입니다.
CASE 구문을 올바르게 사용하기 위해서는 WHEN과 THEN 이후에 모두 식을 적어주어야 합니다.
실제로 THEN 이후에 university 대신 1 또는 2+2 같은 식을 넣어도 쿼리가 정상적으로 수행됩니다.
SELECT, FROM, WHERE, GROUP BY, HAVING, ORDER BY 등 SQL 구문 뒤에 적는 것은 모두 식입니다.
2. 집합 지향형(Set-oriented) 언어
SQL은 집합 지향형 언어입니다.
데이터베이스는 관리를 위해서 정리된 정보의 집합체고, 테이블은 동일한 속성을 가진 데이터의 집합입니다.
SQL은 기본적으로 테이블 단위로 쿼리하기 때문에 쿼리의 수행 결과는 어떤 집합에 대한 데이터입니다.
전체 JOBS 데이터를 쿼리하는 SQL 예시와 출력 결과를 자세히 보겠습니다:
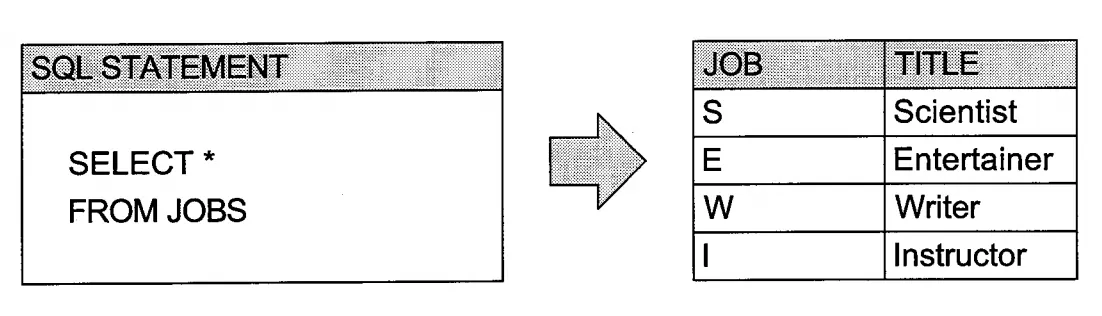
왼쪽 SQL의 수행 결과로 오른쪽의 집합이 반환됩니다.
기본적으로 SQL은 쿼리 수행 결과로 집합에 포함된 원소들을 여러 개의 행으로 반환합니다.
데이터가 존재하지 않거나 한 개의 행만 존재하는 특별한 경우 제외
쿼리를 수행하면 다수의 행으로 표현된 집합 데이터가 반환된다는 사실을 기억합시다.
그럼 SQL의 결과는 항상 다수의 행을 반환할까요?
그건 아닙니다.
SQL을 통해 단일 행의 값을 반환할 수 있습니다.
SQL에서 단일 값을 반환할 때 이를 스칼라 값(scalar value)이라고 칭합니다.
스칼라(Scalar)
스칼라 값을 반환하는 가장 대표적인 경우는 집계 함수(aggregate function)를 사용했을 때입니다.
집계 함수는 집합의 다수 행을 단일 값으로 집약합니다.
집계 함수의 예로는 COUNT, SUM, AVG, MIN, MAX 등이 있습니다.
개별 집계 함수에 대한 자세한 설명은 생략합니다.
다음은 국가의 인구 평균을 구하는 SQL의 예시입니다:
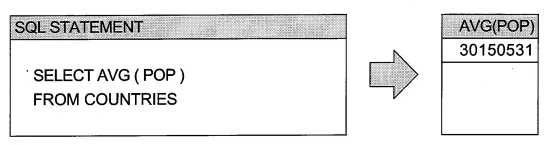
위 SQL의 수행 결과는 전체 국가(COUNTRIES)의 인구(POP) 평균(AVG)을 계산하여 단일 값으로 반환합니다.
모든 국가의 인구 합을 국가의 수로 나눈 결과를 하나의 행으로 반환합니다.
국가 인구 평균(AVG) = 모든 국가 인구 합(POP 합) / 전체 국가 수(전체 행의 수)
스칼라 값이 특별한 이유는 서브 쿼리(sub query)로 이용 가능하기 때문입니다:
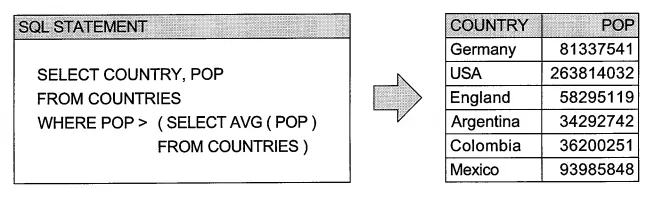
위의 WHERE 절을 보면 쿼리 안에 또 하나의 쿼리가 중첩된 구조를 서브 쿼리라고 부릅니다.
예시를 보면 서브 쿼리에서 계산한 인구의 평균 값이 스칼라 값으로 반환되기 때문에 WHERE 절의 조건으로 사용하여 비교연산(>)을 통해 인구 수가 평균 이상인 국가 이름(COUNTRY)과 인구 수(POP)를 출력하고 있습니다.
GROUP BY
국가 인구 평균을 구하는 SQL에 한 가지 생략된 구문이 있습니다.
바로 GROUP BY입니다.
SQL은 집합 지향적 언어라고 이야기 했습니다.
그렇기 때문에 SQL에는 집합을 조작할 수 있는 구문이 많이 있습니다.
가장 대표적인 집합 지향적 구문이 GROUP BY입니다.
GROUP BY는 GROUP BY `열 이름`과 같은 문법으로 사용됩니다.
GROUP BY를 사용하면 전체 집합을 지정한 열을 기준으로 분류하고 집약합니다.
예를 들어 전체 유저 그룹에 대해 GROUP BY gender로 지정한다면 각 gender 별로 그룹이 분류됩니다.
앞에서 SQL은 기본적으로 다수의 행을 반환한다고 했는데 여기에 GROUP BY `열 이름`을 추가하면 전체 집합의 모든 행을 지정한 열의 값을 기준으로 분류한 뒤 각 집합을 하나의 행으로 집약합니다.
다음 예시를 보면 genre에 대해 GROUP BY 했을 경우,
동일한 genre 값을 갖는 다수의 행을 하나의 집합으로 묶어 각 집합 별 qty의 합(SUM)을 구합니다:
SELECT
genre,
SUM(qty) AS total
FROM
books
GROUP BY
genre
SQL
복사
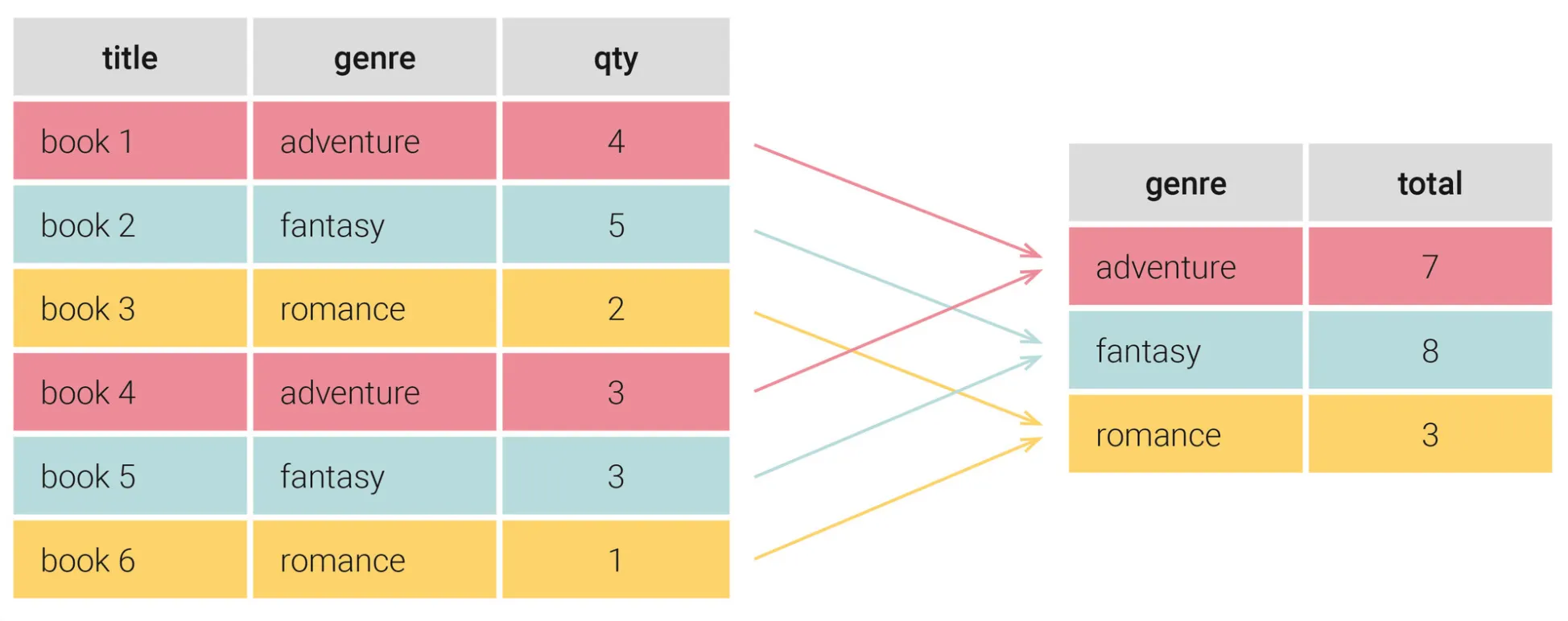
그래서 GROUP BY를 통해 반환되는 행의 수는 특정 열을 기준으로 분류한 집합의 수와 같습니다.
위의 예시에서 전체 집합을 genre 별로 구분하면 adventure, fantasy, romance 각각 세 개의 집합으로 분류되고, 이는 오른쪽 결과에 반환되는 3개의 행의 개수와 같습니다.
GROUP BY를 사용할 때 명심해야 되는 점은 SELECT 구문에는 GROUP BY의 기준이 되는 열 또는 집계 함수만 포함될 수 있습니다.
책을 genre 별로 구분한 위의 예시를 보면 SELECT 구문에 GROUP BY 기준인 genre와 SUM(qty) 집계 함수가 있습니다.
만약 위 쿼리의 SELECT 안에 title을 추가하면 어떻게 될까요?
장르 별로 집약된 책 집합은 다수의 책들로 이루어져 있습니다.
예를 들어 adventure 집합 안에는 book1과 book4가 포함되어 있습니다.
GROUP BY를 통해 집합을 집약하여 하나의 행으로 표현했지만 해당 행은 집합의 데이터입니다.
따라서 장르 별로 집약된 집합에서 하나의 title을 특정할 수 없습니다.
그렇기 때문에 SELECT 안에 title을 추가한 SQL은 정상적으로 동작하지 않습니다.
하나의 title을 출력하고싶다면 MIN() 또는 MAX()를 이용한 특수한 조건을 지정해야 합니다.
전체 국가의 인구 평균을 구하기 위해서는 전체 그룹을 국가 별로 분류하지 않고 하나의 그룹으로 취급해야 합니다.
이를 SQL로 나타내면 GROUP BY '' 입니다.
데이터베이스에 따라 GROUP BY에 빈 열을 지정하는 것을 허용하지 않을 수도 있지만 아래의 설명은 동일하게 적용됩니다.
인구 평균을 구하는 SQL에 아래와 같은 GROUP BY가 생략되어 있습니다.
SELECT AVG(POP)
FROM COUNTRIES
GROUP BY '' -- 생략 가능
SQL
복사
다수의 열을 기준으로 하여 GROUP BY를 수행하는 것도 가능합니다:
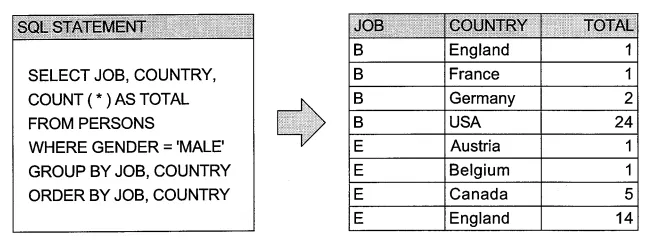
위 SQL은 전체 집합을 JOB과 COUTRY를 기준으로 분류하고 각 집합에 해당하는 행의 개수를 집계합니다.
JOIN
GROUP BY 만큼 중요한 구문이 JOIN입니다.
JOIN을 이용하면 하나의 쿼리로 다수의 테이블에 대한 조회가 가능합니다.
JOIN을 이용하면 다수의 테이블에 대한 쿼리의 결과가 하나의 결과 테이블로 결합됩니다.
적어도 한 개 이상의 공통되는 열이 존재할 때 JOIN을 사용할 수 있습니다.
다음과 같은 두 개의 테이블이 있다고 해보겠습니다:
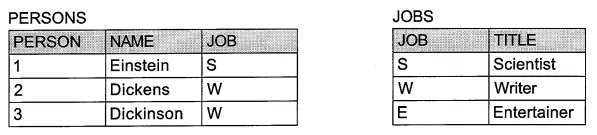
PERSONS 테이블과 JOBS 테이블은 공통적으로 JOB이라는 열을 갖고 있습니다.
두 개의 테이블에 대해 다음과 같은 요구 조건을 가질 수 있습니다:
"인물 이름과 그 사람의 JOB TITLE을 한 번에 보여줘"
이 때 필요한 테크닉이 바로 JOIN입니다.
JOIN을 이용하면 공통의 JOB 열을 이용하여 두 개의 테이블을 연결할 수 있습니다.
먼저 이를 SQL로 표현하면 다음과 같습니다:
SELECT
PERSON,
NAME,
JOB,
TITLE
FROM
PERSONS
INNER JOIN
JOBS
ON
PERSONS.JOB = JOBS.JOB
SQL
복사
PERSONS 테이블에 JOBS 테이블의 데이터를 함께 나타내는데 공통의 JOB 열을 이용한다고 이해하면 됩니다.
ON 절에 올바르게 적기만 하면 공통되는 열의 이름은 서로 달라도 됩니다.
실제로 JOIN이 이루어지는 과정을 단계 별로 나누어서 이해해보겠습니다:
1.
두 개의 테이블의 행으로 만들 수 있는 모든 조합을 구합니다.
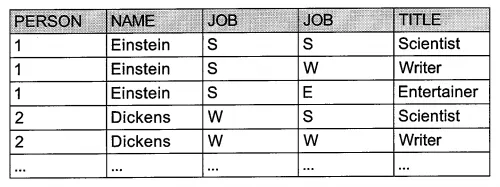
이런 집합 간의 연산을 흔히 곱집합 또는 데카르트 곱(cartesian product)이라고 부릅니다.
PERSONS 테이블과 JOBS 테이블의 행의 수가 각각 3개이기 때문에 곱집합의 행의 수는 3X3=9개가 됩니다.
2. 곱집합 중에서 JOB의 값이 같은 행을 추출합니다.
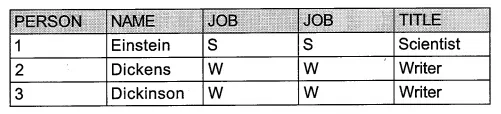
두 테이블을 JOB 열로 연결하기 때문에 전체 9개의 행 중에서 JOB의 값이 같은 행만 추출됩니다.
3. 중복되는 JOB 열을 제거하고 결과를 출력합니다.
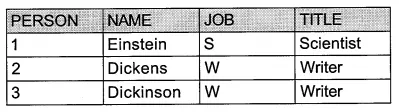
최종 출력되는 열은 SELECT에 선언한 열들입니다.
JOIN을 이용하면 두 개의 테이블의 데이터를 마치 한 개의 테이블의 데이터인 것처럼 나타낼 수 있습니다.
JOIN에는 지금 사용한 INNER JOIN 외에도 LEFT JOIN, RIGHT JOIN, FULL OUTER JOIN 등이 있는데
각각의 JOIN은 결과 집합을 선택하는 기준이 다를 뿐 곱집합과 공통 열을 이용하여 유도하는 방식은 동일합니다.
Window 함수
앞서 GROUP BY를 이용하면 집합을 조작할 수 있다고 배웠습니다.
GROUP BY는 집약한 집합의 결과를 하나의 행으로 반환합니다.
그런데 개별 행의 값과 집계된 결과를 함께 보고싶으면 어떻게 할까요?
예를 들어 아래와 같은 경우입니다:
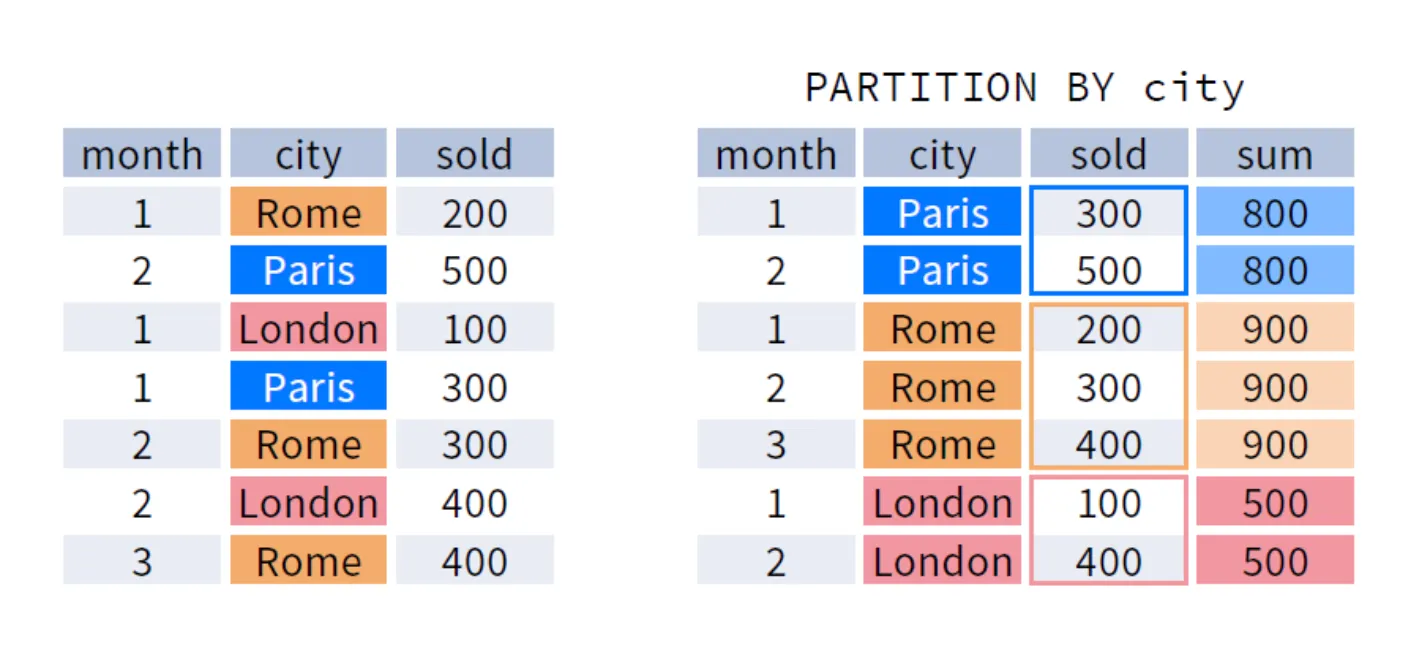
왼쪽 테이블은 지점별 월간 매출이라고 생각해봅시다. 오른쪽은 출력하고 싶은 결과 예시입니다.
오른쪽 결과는 지점별 월간 매출과 함께 해당 지점의 매출 합(SUM)을 함께 출력하고 있습니다.
GROUP BY city를 이용하면 각 도시의 매출 합계를 한 번에 볼 수 있지만,
GROUP BY 예시
오른쪽 예시처럼 월별 매출을 원래대로 보여주면서 합계를 나타내는 열을 추가하려면 어떻게 해야할까요?
이 때 필요한 기능은 Window 함수입니다.
Window 함수를 이용하면 집합의 데이터를 집계해서 원본 테이블에 새로운 열로 추가할 수 있습니다.
GROUP BY의 결과는 집합의 데이터를 한 개의 행으로 반환하는데 반해 Window 함수는 집합이 하나의 행으로 집약되지 않고 출력되는 행의 수가 원래 테이블의 행의 수와 같습니다.
Window 함수의 기본 문법은 <집약 함수> OVER (PARTITION BY `열 이름`) 입니다.
문법만 보면 다소 어려워보이지만 무작정 외우려고 하지말고 먼저 이해하면 기억하기 더 쉽습니다.
기존 집약함수와 구분하기 위해 집약함수 뒤에 OVER를 추가합니다.
그리고 GROUP BY에서 집합을 분류할 열을 지정했던 것처럼 PARTITION BY `열 이름`을 추가하면 됩니다.
오른쪽 결과 예시처럼 출력하기 위해서는 다음과 같은 SQL을 이용하면 됩니다:
SELECT
month,
city,
sold,
SUM(sold) OVER (PARTITION BY city ORDER BY month ASC) AS sum
FROM
SALES
SQL
복사
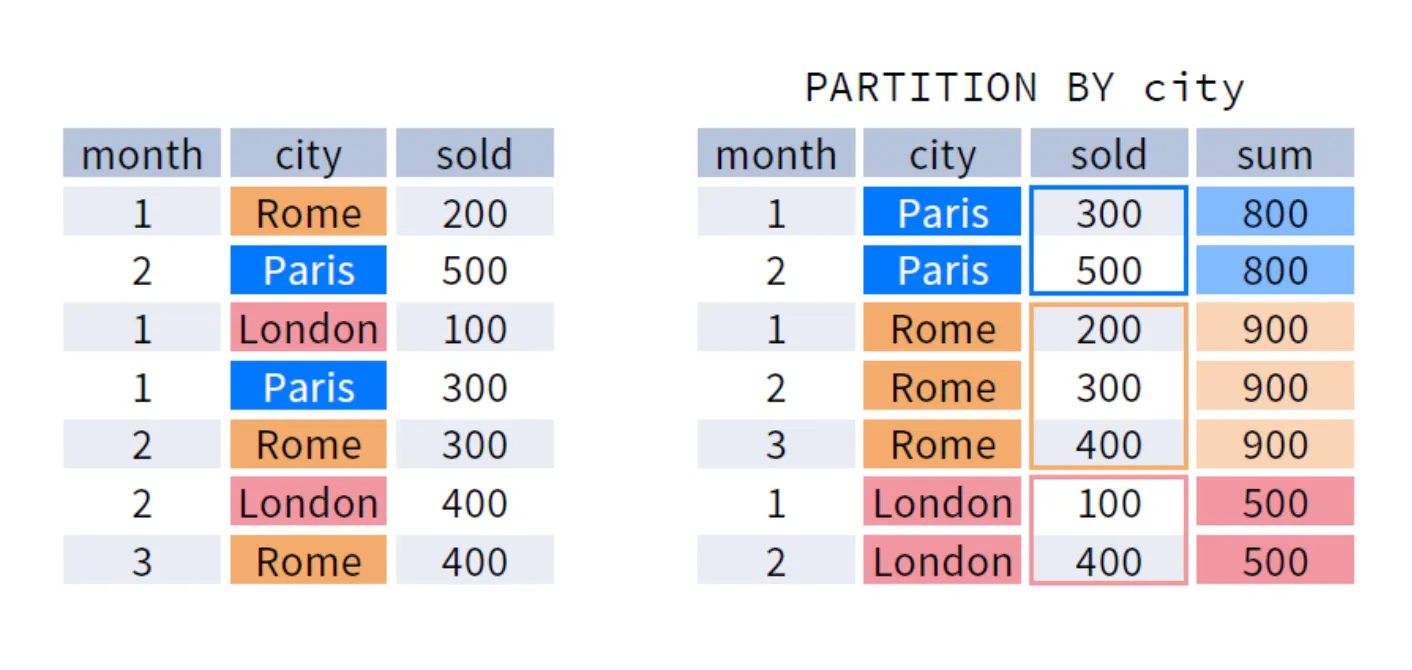
위의 SQL의 결과로 city 별 sold의 합계가 새로운 열로 추가 됩니다.
또 OVER() 안에 ORDER BY를 지정할 경우 각 그룹 안에서 결과 값이 해당 열을 기준으로 정렬됩니다.
Windonw 함수에서도 PARTITION BY를 지정하지 않으면 전체 집합에 대한 집계가 가능합니다:
SELECT
month,
city,
sold,
SUM(sold) OVER () AS total_sum
FROM
SALES
SQL
복사
LEVEL UP
지금까지 배운 것을 활용해 몇 가지 문제를 해결해봅시다.
앞으로 다룰 내용은 자주 사용되는 쿼리 패턴들이기 때문에 가급적 모두 익혀둡시다.
1. LAG, LEAD
LAG와 LEAD는 모두 Window 함수로 각각 현재 행 이전 행과 이후 행의 데이터에 접근 할 수 있습니다.
기본 문법은 다음과 같습니다:
LAG( 표현식, offset ) OVER ( [PARTITION BY] ORDER BY )
LEAD( 표현식, offset ) OVER ( [PARTITION BY] ORDER BY )
지금까지 표현식과 Window 함수에 대해서 배웠기 때문에 위의 문법을 이해하는데 큰 문제는 없을 것입니다.
한 가지 추가된 점은 offset입니다.
offset은 몇 번째 이전(또는 이후) 행에 대해 접근할 지를 정수로 나타냅니다.
예시를 보겠습니다.
다음과 같이 LAG를 이용하면 직전 분기(quarter)의 매출(sales)을 함께 볼 수 있습니다:
SELECT
*,
LAG(sales, 1) OVER (ORDER BY year, quarter ASC) AS last_quarter_sales
FROM
SALES
SQL
복사
<원본>
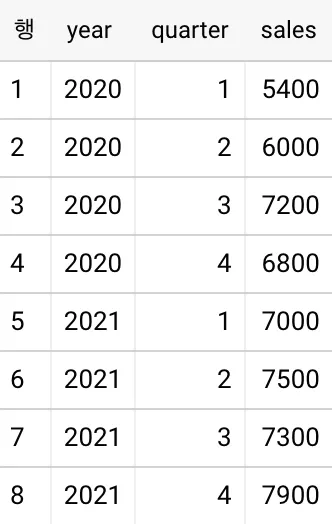
<결과>
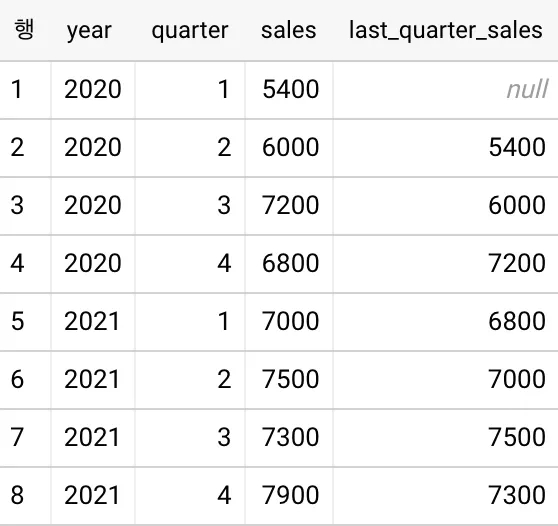
last_quarter_sales의 값이 모두 이전 행의 sales 값과 같습니다.
위의 예시에서 출력 조건을 바꾸어보겠습니다.
"각 연도 별로 직전 분기와의 매출 차이를 함께 출력하라"
결과부터 확인하면 다음과 같습니다:
<원본>
<결과>
SELECT
*,
sales - LAG(sales, 1) OVER (PARTITION BY year ORDER BY year, quarter ASC) AS sales_delta
FROM
SALES
SQL
복사
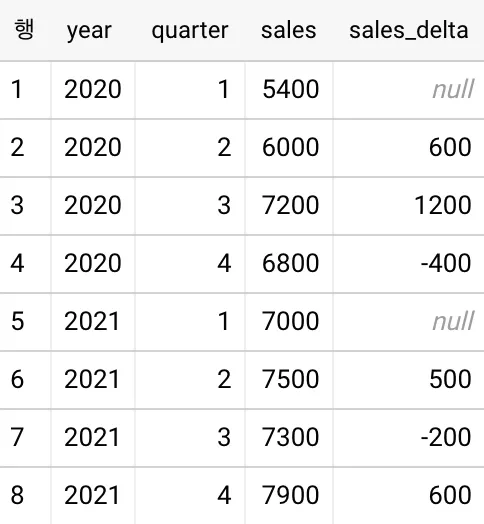
몇 가지 유의깊게 봐야되는 점에 대해서 짚고 가겠습니다.
1.
LAG()의 결과를 다시 - 연산하여 SELECT 구문 안에 sales - LAG()처럼 표현식으로 나타냈습니다.
2.
LAG() 안에서 PARTION BY를 통해 연도 별로 분류하였기 때문에
5번째 행(2021년)은 이전 행(2020년)과의 연산이 불가능하여 null로 출력되었습니다.
3.
sales_delta의 값은 현재 행의 sales - 이전 행의 sales입니다.
2. Rolling AVG
Sliding Window라고 불리는 테크닉입니다.
KOSPI 데이터의 지난 3일 간의 이동 평균을 구해보겠습니다:
<원본>
<결과>
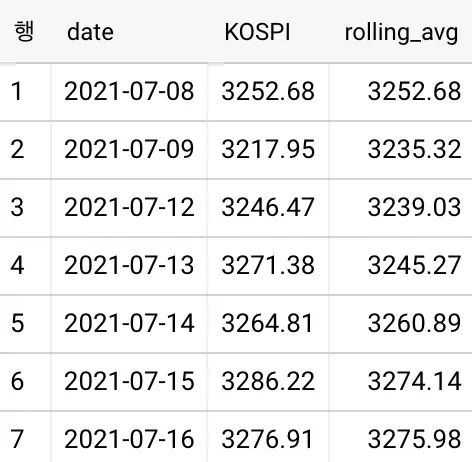
이동평균(rolling_avg)이 익숙하지 않은 분들을 위해 결과 값에 대해 간단히 설명하겠습니다.
각 행의 rolling_avg 값은 이전 2개의 행과 현재 행의 KOSPI 평균입니다.
예를 들어 7번째 행의 이동평균 값인 3275.98은 다음과 같이 계산됩니다.
→ (5번째 행의 KOSPI + 6번째 행의 KOSPI + 7번째 행의 KOSPI) / 3
→ (3264.81 + 3286.22 + 3276.91) / 3 = 3275.98
이전의 모든 행들도 같은 방식으로 계산됩니다.
1행과 2행처럼 이전 2개의 행이 존재하지 않는 경우는 존재하는 행만으로 계산합니다.
이를 위한 SQL은 다음과 같습니다:
SELECT
*,
AVG(KOSPI) OVER (ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) AS rolling_avg
FROM
SALES
SQL
복사
결과 이미지는 소수점 두번째자리까지만 출력하기 위해 ROUND()를 사용했습니다.
SQL 예시에는 원활한 설명을 위해 ROUND()를 제거했습니다.
실제 사용한 SQL
Window 함수 안에서 ROWS BETWEEN 문법을 이용하면 앞서 얘기한 LAG나 LEAD처럼 이전 행 또는 이후 행에 대한 집계를 수행할 수 있습니다.
ROWS BETWEEN + 2 PRECEDING + AND + CURRENT ROW를 보면 2개 이전 행과 현재 행에 대해 AVG()를 계산한다는 것을 알 수 있습니다.
3. Window 함수 + CASE 구문
Window 함수 안에서 CASE 구문을 이용하여 복잡한 요구조건을 해결해보도록 하겠습니다.
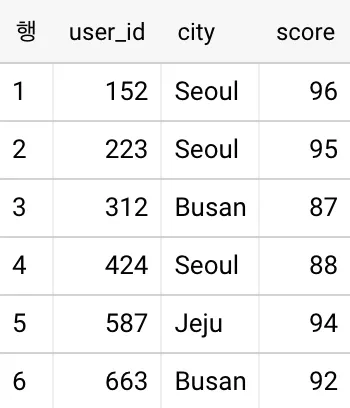
유저들로부터 응모를 받아 점수에 따라 경품 당첨 순서를 정한다고 하겠습니다.
<원본>
<결과>
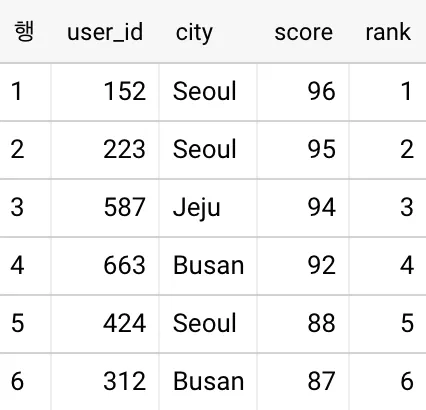
점수에 따라 유저의 순서를 정하려면 Window 함수인 rank()를 사용하면 됩니다:
SELECT
*,
RANK() OVER (ORDER BY score DESC) AS rank
FROM
DRAWS
SQL
복사
유저가 점수에 따라 정렬되고 당첨 순서를 나타내는 rank 필드가 새롭게 추가된 것을 볼 수 있습니다.
만약 당첨시 서울이 아닌 지역의 유저가 우선순위를 갖는다고 해봅시다.
우선순위를 제외하면 점수에 따라 당첨 순서가 결정되는 방식은 동일합니다.
예상되는 출력 결과는 다음과 같습니다:
<원본>
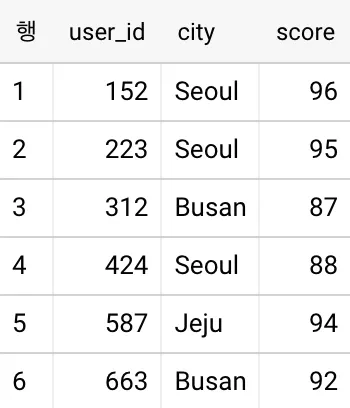
<결과>
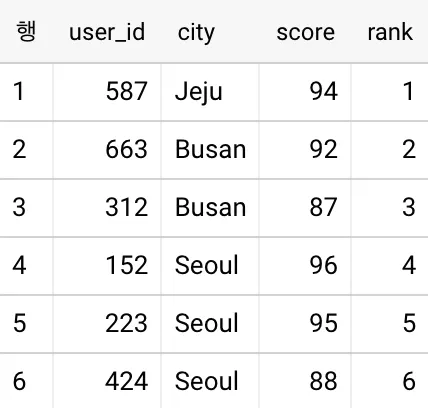
도시가 서울인 유저(4~6행)는 다른 지역의 유저보다 점수가 높음에도 불구하고 당첨 순위가 낮게 배정 됐습니다.
위와 같은 쿼리를 위해서는 점수에 따른 정렬 이전에 도시에 따른 정렬을 추가해주면 됩니다.
도시가 서울인 경우와 서울이 아닌 경우로 구분할 수 있습니다.
서울인 경우는 낮은 우선순위를, 서울이 아닌 경우에는 높은 우선순위를 주어 이를 정렬하면 됩니다.
도시가 서울인지 아닌지 여부에 따라 정렬하기 위해 ORDER BY 안에 CASE 문을 사용해봅시다.
이를 SQL로 표현하면 다음과 같습니다:
SELECT
*,
RANK() OVER (ORDER BY CASE WHEN city != 'Seoul' then 0 ELSE 1 END ASC, score DESC) AS rank
FROM
DRAWS
SQL
복사
추가된 부분을 보면 서울이 아닌 도시는 0, 서울은 1로 표현하고 이를 오름차순 정렬합니다.
점수로 정렬하기 전 유저의 도시에 따라 0과 1로 표현된 값으로 먼저 정렬하여 위와 같은 결과를 얻을 수 있습니다.
이후 score DESC로 지정한 기본 조건은 동일합니다.
4. CTE
마지막으로 알아볼 테크닉은 Common Table Expression, 줄여서 CTE입니다.
CTE는 일시적으로 생성된 쿼리의 결과 데이터 집합을 일컫는 말입니다.
CTE의 문법은 다음과 같습니다:
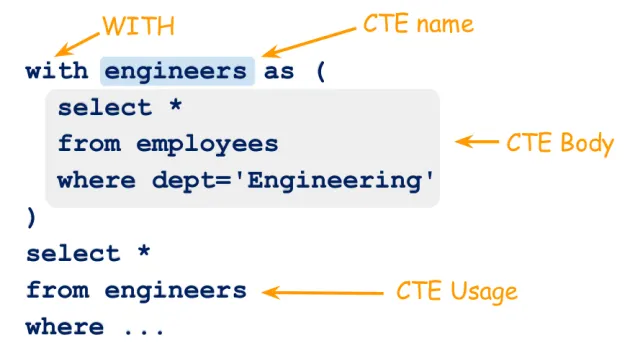
WITH로 시작하여 CTE Body까지가 CTE입니다.
AS() 안의 쿼리에 따라 engineers라는 이름의 결과 집합이 일시적으로 생성됩니다.
CTE로 만들어진 결과 engineers는 CTE Usage 부분의 FROM 절 등에서 사용 가능합니다.
CTE의 결과는 데이터베이스에 저장되지 않고, 쿼리가 수행되는 동안에만 존재합니다.
CTE를 이용하면 다음과 같은 장점이 있습니다:
1.
SQL이 구조화 되고 가독성이 높아진다.
2.
임시 추출한 결과를 쉽게 재사용할 수 있다.
3.
Recursive CTE를 이용하여 재귀적인 결과를 도출할 수 있다. 이번 포스트에서는 다루지 않습니다.
CTE는 서브 쿼리처럼 임시 데이터를 생성하여 쿼리 안에서 사용한다는 공통점이 있습니다.
하지만 CTE는 서브 쿼리보다 가독성이 좋고, 데이터를 여러번 재사용 할 수 있습니다.
CTE를 사용하는 예시를 알아봅시다.
각 집합을 대표하는 책 이름을 뽑으려면 MIN() 또는 MAX()를 사용하면 된다고 얘기했습니다.
SELECT
genre,
SUM(qty) AS total,
MIN(title) AS title_min,
MAX(title) AS title_max
FROM books
GROUP BY genre
SQL
복사
<원본>
<결과>
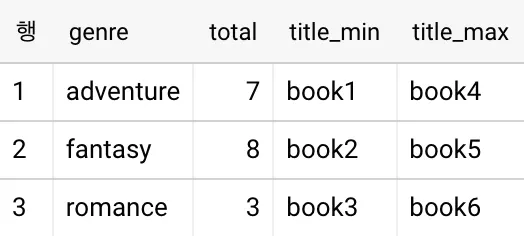
각 집합의 title을 알파벳 순으로 정렬하여 최소값 또는 최댓값을 반환한 결과입니다.
각 집합의 대표 title을 가장 높은 qty를 가진 책의 이름으로 출력되게 해봅시다.
각 행의 순서를 나타내려면 이전에 배운 WINDOW 함수를 활용하면 됩니다.
문제는 위의 출력 결과는 GROUP BY 된 결과이기 때문에 WINDOW 함수를 함께 사용할 수 없습니다.
GROUP BY를 없애고 각 집합의 수량 합인 total과 qty에 따른 행의 순서를 WINDOW 함수로 표현해봅시다.
SELECT
*,
SUM(qty) OVER (PARTITION by genre) AS total,
ROW_NUMBER() OVER(PARTITION by genre ORDER BY qty DESC) AS row_num
FROM books
SQL
복사
GROUP BY genre를 제거했기 때문에 각 WINDOW 함수의 PARTITION BY에 genre가 추가 됐습니다.
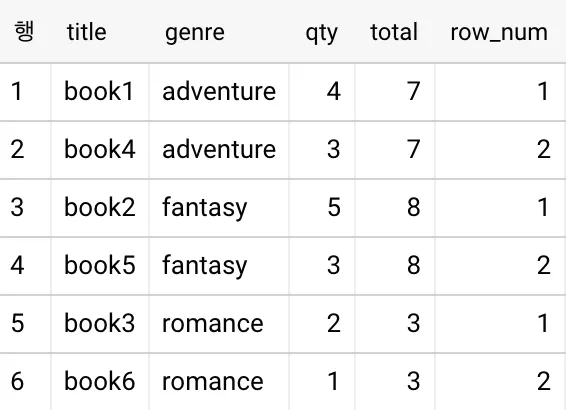
이제 각 그룹의 row_num이 1인 행만 추출하면 됩니다.
이 때 CTE를 사용하면 다음과 같은 쿼리를 작성할 수 있습니다:
WITH aggregated_books AS (
SELECT
genre,
title,
SUM(qty) OVER (partition by genre) AS total,
ROW_NUMBER() OVER(partition by genre ORDER BY qty DESC) AS row_num
FROM books
)
SELECT genre, total, title
FROM aggregated_books
WHERE row_num = 1
SQL
복사
<원본>
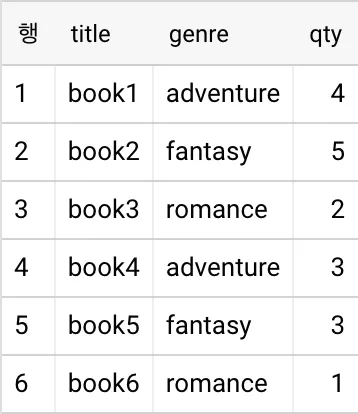
<결과>
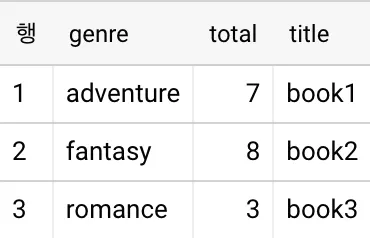
혼동을 줄이기 위해 덧붙이자면 위의 예시의 경우 반드시 CTE를 이용해야 하는 건 아닙니다.
CTE를 그대로 서브쿼리로 만들어 FROM 절 안에 사용하는 방법도 가능합니다.
Exercises
위에서 배운 내용을 기반으로 한 intermediate 수준의 SQL 인터뷰 문제 풀이입니다.

또 지금까지 배운 내용을 연습하기 좋은 영상이 있어서 공유합니다.






