



목차
Intro
지난 글에서는 SQL의 특성을 통해 ORM 사용시 실수하기 쉬운 부분에 대해서 되짚어 봤습니다.
이번 글에서는 index를 활용하는 방법과 같은 실용적인 ORM 사용법을 알아보겠습니다.
Index
Index를 이용하면 데이터를 읽어오는 속도를 향상 시킬 수 있습니다.
하지만 index를 관리(생성, 수정, 삭제)하기 위해 데이터베이스는 수많은 백그라운드 작업을 수행합니다.
Index를 추가하는 것은 읽기 속도를 향상 시키기 위해 다른 작업에서 발생하는 부하를 희생하는 것입니다.
따라서 무분별하게 index를 추가해서는 안 되고, 필요한 부분에 index를 잘 설계하는 것이 중요합니다.
특히 MySQL는 업데이트시 index를 통해 lock을 잡습니다.
따라서 index가 올바르게 설계되어있지 않은 경우, 최악의 경우 전체 테이블에 lock이 잡힐 수도 있습니다.
다만 index를 추가했다고 반드시 데이터를 읽는 속도가 향상되는 것은 아닙니다.
Index를 잘 설계하는 것 만큼이나 index가 제대로 동작할 수 있도록 쿼리하는 것이 중요합니다.
효율적으로 index를 설계하는 법과 index를 제대로 활용할 수 있는 ORM 사용법을 알아봅시다.

MySQL을 기준으로 설명합니다.
Index에 대한 내용은 너무 방대하기 때문에 일부 자세한 설명은 생략될 수 있습니다.
아래의 설명을 토대로 따로 index를 공부해볼 것을 권장합니다.
Index 설계
먼저 효율적인 index를 설계 방법부터 알아보겠습니다.
주의할 점은 데이터의 특성이나 쿼리 방법에 따라 좋은 index 설계는 다를 수 있습니다.
따라서 index의 특성을 이해해야 필요에 맞게 효율적인 index를 설계할 수 있습니다.
Cardinality
일반적으로 cardinality가 높은 컬럼을 index로 추가하는 것이 좋습니다.
Cardinality가 높으면 해당 컬럼으로 인해 레코드가 쉽게 분류되기 때문에 index 효율이 좋습니다.
예를 들어, 주민등록번호와 성별 컬럼이 있다고 합시다.
주민등록번호는 고유한 값이기 때문에 index를 만들어 조회하면 빠르게 한 명의 유저를 찾을 수 있습니다
이에 반해, 성별은 중복도가 높기 때문에 성별로만 한 명의 유저를 특정할 수 없습니다.
하지만 주민등록번호로 유저를 조회하는 경우가 없다면 index를 추가하지 않는 것이 낫습니다.
불필요한 index를 추가하는 것은 레코드의 생성, 수정, 삭제 작업에 불필요한 부하를 더하는 것입니다.
Usage
조회, 정렬, GROUP BY에 자주 사용되는 컬럼은 index를 추가를 고려해볼만 합니다.
ORM 메소드로 보면 filter(), order_by(), values() 등 입니다.
Index는 항상 정렬되어 있는데 ORDER BY로 결과를 정렬하는 경우, index의 정렬을 활용할 수 있습니다.
예를 들어, 주소에서 서울을 조회 할 때 결과를 구 단위로 오름차순 정렬한다고 합시다.
조회에는 도시명만 필요하지만 정렬을 위해 도시+구로 다중 컬럼 인덱스를 생성하면 조회 속도가 향상됩니다.
GROUP BY의 경우에도 동일한 집합을 분류하기 위해 먼저 레코드를 정렬하기 때문에 index가 있으면 좋습니다.
하지만 반드시 실행 계획을 분석해보고 데이터의 특성에 맞게 인덱스를 추가하는 것이 나을지 고려합시다.
또 읽기 속도보다 쓰기 속도가 중요하다면, index를 추가하는 것을 고민해보아야 합니다.
Unique 제약
테이블 내에서 unique하게 존재해야 하는 값이 있는 경우 컬럼에 unique 제약을 걸 수 있습니다.
Django 모델의 메타 클래스에 아래와 같은 방법으로 선언하면 됩니다.
class Foo(models.Model):
...
class Meta:
constraints = [
models.UniqueConstraint(fields=['single_column']),
models.UniqueConstraint(fields=['multi', 'column']),
]
Python
복사
Unique 제약을 걸 경우, 자동으로 index가 추가됩니다.
따라서 unique 제약이 있는 컬럼은 별도로 index를 추가할 필요가 없습니다.
다중 컬럼을 통해 unique 제약을 추가하면 이는 다중 컬럼 인덱스의 역할을 합니다.
따라서 여러 개의 컬럼에 한 번에 unique 제약을 걸 때는 컬럼의 순서를 고려하여 설계합시다.
자세한 내용은 아래 다중 컬럼 인덱스에서 얘기하겠습니다.
다중 컬럼 인덱스
Index는 Django 모델의 메타 클래스에 아래와 같이 추가할 수 있습니다.
class Foo(models.Model):
...
class Meta:
indexes = [
models.Index(fields=['single_column']),
models.Index(fields=['multi', 'column']),
]
Python
복사
Unique 제약과 index는 필드의 옵션으로 지정할 수도 있는데, 각 필드에 옵션으로 지정하는 것 보다는 메타 클래스를 통해서 한 번에 관리하는 것이 낫습니다. 필드 옵션은 다중 컬럼에 대한 unique 제약, index 추가 등을 지정할 수 없습니다.
class Foo(models.Model):
bar = models.CharField(max_length=1, db_index=True, unique=True)
Python
복사
다중 컬럼 인덱스를 설계할 때는 index 내의 컬럼 순서가 매우 중요합니다.
데이터를 조회할 때, 동치 조건과 비교 표현식이 있다면 동치 조건을 사용하는 컬럼을 앞에 둡시다.
예를 들어, 주문 테이블에서 상품 번호와 주문 날짜로 아래와 같이 조회한다고 합시다.
SELECT
*
FROM
Order
WHERE
product_id = 1
AND ordered_at BETWEEN '2022-05-01' AND '2022-05-02'
SQL
복사
이 때 index를 제대로 사용하기 위해서는 다중 컬럼 인덱스의 선행 컬럼으로 상품 번호를 지정해야 합니다.
class Order(models.Model):
...
class Meta:
indexes = [
models.Index(fields=['product', 'ordered_at']),
]
Python
복사
1.
상품 번호가 선행 컬럼인 경우,
특정 상품을 먼저 찾고, 주문 날짜의 범위에 해당하는 레코드만 조회한 뒤에 탐색을 종료하지만
2.
주문 날짜가 선행 컬럼인 경우,
해당 날짜의 범위를 내에서 상품을 찾을 때까지 상품 번호를 비교하는 과정을 거치기 때문입니다.
한 가지 예시를 더 들어보겠습니다.
출입 명부에서 귀도 반 로썸이라는 사람이 5월 1일부터 2일까지 출입한 기록을 찾는다고 합시다.
이 때, 출입 명부가 이름 + 출입일로 정렬되어 있는 것과 출입일 + 이름으로 정렬되어 있는 차이입니다.
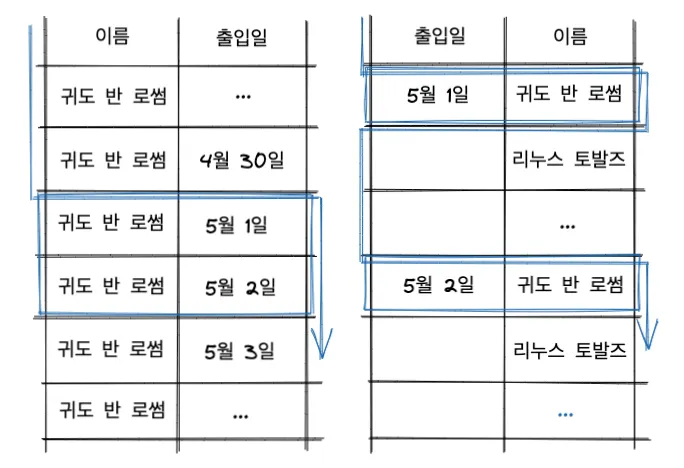
파란색 선이 조건에 맞는 레코드를 찾는 여러분의 시선 흐름입니다.
이는 데이터베이스가 레코드를 탐색하는 경로이기도 합니다.
이름이 먼저 정렬되어 있는 경우, 이름을 찾고 출입일의 범위 만큼만 탐색하면 됩니다.
하지만 출입일이 먼저 정렬된 경우, 출입일 마다 전체 회원 중에서 원하는 이름을 찾아야 합니다.
조회하는 날짜의 범위가 예시보다 더 큰 경우를 상상해보면 어떤 것이 더 효율적인지 바로 이해가 될 것입니다.
Index를 활용하기 위한 쿼리
이제 index를 활용하여 쿼리할 수 있는 방법에 대해서 알아보겠습니다.
컬럼을 수정하여 조회하는 경우
Index가 생성된 컬럼에 대해 쿼리할 때, 해당 컬럼을 수정하여 조회하게 되면 index를 제대로 활용할 수 없습니다.
가장 대표적인 예시는 LIKE 문으로 조회하는 경우입니다.
# indexes = [models.Index(fields=['name'])]
>>> User.objects.filter(name__contains='Guido')
Python
복사
SELECT
*
FROM
User
WHERE
name LIKE '%Guido%'
SQL
복사
CharField에 대해 __contains field lookup을 사용하면 LIKE문으로 대체됩니다.
LIKE문의 경우, 패턴에 맞는 문자열을 탐색하는데 %는 모든 문자를 나타냅니다.
따라서 index가 이름으로 정렬되어 있어도 모든 문자로 시작하는 경우를 탐색하기 때문에 index가 무시됩니다.
만약 Guido로 시작하는 이름을 찾고자한다면, __contains 대신 __startswith를 사용합시다.
# indexes = [models.Index(fields=['name'])]
>>> User.objects.filter(name__startswith='Guido')
Python
복사
SELECT * FROM User WHERE name LIKE 'Guido%'
SQL
복사
위와 같이 left-anchored 된 LIKE문을 사용할 경우, index에서 필요한 문자열을 탐색할 수 있습니다.
또 아래와 같이 날짜 컬럼을 수정하여 조회하는 경우도 index가 사용되지 않습니다.
# indexes = [models.Index(fields=['joined_at'])]
>>> User.objects.filter(joined_at__year=2022)
Python
복사
SELECT * FROM User WHERE YEAR(joined_at) = '2022'
SQL
복사
이럴 땐 조회하는 컬럼을 수정하지 않도록 아래와 같이 쿼리합시다.
# indexes = [models.Index(fields=['joined_at'])]
>>> User.objects.filter(joined_at__gte='2022-01-01', joined_at__lt='2023-01-01')
Python
복사
SELECT * FROM User
WHERE joined_at >= '2022-01-01' AND joined_at < '2023-01-01'
SQL
복사
커버링 인덱스
Index 탐색시 MySQL의 클러스터링 인덱스 특성으로 인해 원본 테이블에서 필요한 데이터를 다시 조회합니다.
그런데 만약 index 레코드에 조회에 필요한 모든 컬럼이 있으면, 추가적으로 원본 테이블을 조회하지 않습니다.
이런 경우 원본 테이블을 추가적으로 조회하지 않고 즉시 결과를 반환하기 때문에 조회 속도가 훨씬 빠릅니다.
이처럼 쿼리에 필요한 모든 데이터를 갖고 있는 index를 커버링 인덱스라고 부릅니다.
만약 커버링 인덱스를 통해 필요한 데이터를 모두 조회할 수 있는 경우, 이를 적극 활용합시다.
예를 들어, 조건에 맞는 상품 번호와 주문 날짜를 출력하는 경우입니다.
# indexes = [models.Index(fields=['product', 'ordered_at'])]
queryset = (
Order.objects
.filter(product_id=1, ordered_at__gte='2022-01-01)
.only('product', 'ordered_at')
)
Python
복사
only()를 통해 필요한 컬럼만 지정하면, 커버링 인덱스에서 결과 데이터를 바로 반환하여 매우 빠릅니다.
스캔 범위 줄이기
전체 테이블을 조회해야 하는 경우 index가 추가되어 있는 컬럼을 이용해서 스캔 범위를 줄일 수 있습니다.
예를 들어, 다음과 같은 주문 테이블이 있다고 합시다.
class Order(models.Model):
...
ordered_at = models.DateTimeField(auto_now_add=True, db_index=True)
paid_at = models.DateTimeField(null=True, db_index=False)
Python
복사
만약 결제가 되지 않은 주문에 대해서 매일 아침 이메일을 발송한다고 합시다.
결제되지 않은 주문을 다음과 같이 조회할 수 있습니다.
>>> Order.objects.filter(paid_at__isnull=True)
Python
복사
문제는 paid_at 컬럼에 index가 없기 때문에 쿼리의 스캔 대상이 전체 레코드가 된다는 것입니다.
가장 간단한 해결 방법은 paid_at 컬럼에 index를 추가하는 것입니다.
그런데 주문 레코드가 10억개 이상이고, 미결제 주문을 조회하는 경우는 매일 딱 한 번 뿐이라고 합시다.
위와 같은 상황에서는 paid_at에 index를 추가하는 것은 좋은 해결책이 아닙니다.
자주 사용되지 않는 쿼리를 위해 굳이 index를 추가할 필요가 없습니다.
그럼에도 불구하고 미결제 주문을 빠르게 조회하는게 매우 중요하다면, index를 추가하면 됩니다.
위의 문제를 해결할 수 있는 다른 방법은 index를 통해 스캔 범위를 줄여주는 것입니다.
만약 주문 날짜로 생성된 index가 있다면 유효한 조회 범위만 지정해주는 것이 좋습니다.
예를 들어, 2021년까지의 모든 레코드는 결제가 완료되었다고 합시다. (또는 처리하지 않기로 했다고 합시다)
그렇다면 아래와 같은 방법으로 쿼리하면, 훨씬 빠르게 데이터를 조회할 수 있습니다.
>>> Order.objects.filter(paid_at__isnull=True, orderd_at__gte='2022-01-01')
Python
복사
Index가 추가된 적절한 컬럼이 없다면, PK를 이용하면 됩니다.
PK에는 기본적으로 index가 추가되어 있기 때문입니다.
>>> Order.objects.filter(paid_at__isnull=True, pk__gte=50_000)
Python
복사
결과를 알고보면 뻔한 해결책 같습니다.
하지만 위와 같은 상황에서 생각보다 스캔 범위를 고려하지 않고 쿼리하는 경우가 자주 있습니다.
여기서 핵심은 index가 있는 컬럼을 통해 범위를 줄여준다는 것입니다.
만일 index가 추가되지 않은 컬럼으로 위와 같이 쿼리한다면 이전처럼 전체 레코드를 풀스캔 할 것입니다.
오히려 불필요한 조건이 추가되어 더 무거운 쿼리가 될 수도 있습니다.
ORM 응용
ORM을 응용하여 효율적으로 쿼리할 수 있는 몇 가지 방법을 소개합니다.
Search order
전체 도시 중에서 서울을 항상 앞에 노출하고 싶다고 합시다.
is_primary와 같은 boolean 컬럼을 추가한 뒤 정렬하여 사용하는 것이 가장 일반적인 방법일 것입니다.
앞선 결제의 예시처럼 새로운 컬럼을 추가하는 것이 불필요한 오버헤드가 될 수도 있습니다.
이번에도 별도의 컬럼을 추가하지 않고, SQL을 통해서만 문제를 해결하겠습니다.
CASE WHEN을 활용하면 다음과 같은 쿼리를 통해 특정 조건의 레코드를 기준으로 정렬할 수 있습니다.
cities = (
City.objects
.annotate(
search_order=Case(
When(name='Seoul', then=Value(1)),
default=Value(0),
output_field=IntegerField(),
)
)
.order_by('-search_order')
)
Python
복사
SELECT
*,
CASE
WHEN name = 'Seoul' THEN 1
ELSE 0
END AS search_order
FROM
City
ORDER BY
search_order DESC
SQL
복사
다만 정렬에도 index를 이용할 수 있다고 얘기했습니다.
위 쿼리는 index 정렬을 활용할 수 없고, 결과 레코드의 alias를 이용하여 추가적인 정렬을 수행해야 합니다.
따라서 정렬 과정에서의 부하를 인지하고 사용하도록 합시다.
Dynamic annotation
annotate() 메소드를 이용하면 결과 집합에 컬럼을 추가하여 데이터를 수평 확장할 수 있습니다.
날짜 별로 게시물에 달린 댓글 수를 확인하고 싶다고 합시다.
다음과 같은 테크닉을 활용하면 반복문을 통해 동적으로 annotation을 추가할 수 있습니다.
from datetime import date, timedelta
start_date = date(2022, 1, 1)
end_date = date(2022, 1, 31)
date_range = [
start_date + timedelta(days=x) for x in range((end_date - start_date).days + 1)
]
posts = Post.objects.all()
for _date in date_range:
posts = posts.annotate(
**{
str(_date): Coalesce(
Count('id', filter=Q(
comments__created_at__lt=_date + timedelta(days=1)
)
), 0
)
}
)
Python
복사
SELECT
*,
COALESCE( COUNT(
CASE
WHEN created_at < '2022-01-02 00:00:00' THEN id
ELSE
NULL
END
),
0) AS '2022-01-01',
COALESCE( COUNT(
CASE
WHEN created_at < '2022-01-03 00:00:00' THEN id
ELSE
NULL
END
),
0) AS '2022-01-02',
...
FROM
Post
INNER JOIN
Comment
ON
Post.id = Comment.post_id
GROUP BY
Post.id
ORDER BY
NULL
SQL
복사
반복문으로 annotation을 추가해도 lazy loading 방식으로 인해 여러번 쿼리가 발생하지 않습니다.
위와 같이 annotation을 추가했을 때 장점은 한 번의 쿼리로 필요한 모든 데이터를 가져올 수 있다는 것입니다.
동적으로 추가한 annoation이 모두 SELECT문 안에 CASE WHEN문으로 추가 되었습니다.
따라서 Comment 테이블과 한 번의 JOIN 만으로 조건에 해당하는 모든 데이터를 가져올 수 있습니다.

